Merlin简要使用手册¶
Merlin的简要介绍 Merlin不是一个完整的TTS系统,它只是提供了TTS核心的声学建模模块(声学和语音特征归一化,神经网络声学模型训练和生成)。
前端文本处理(frontend)和声码器(vocoder)需要其他软件辅助。
- frontend:
- festival
- festvox
- hts
- htk
- vocoder:
- WORLD
- SPTK
- MagPhase
1 Merlin的安装¶
安装
Merlin只能在unix类系统下运行,使用Python,并用theano作为后端
Merlin的Python语言采用的是Python2.7编写(更新:merlin已经支持python2.7-3.6 的版本),所以我们需要在Python2.7的环境下运行Merlin,为避免python不同版本之间的冲突,我们采用Anaconda对Python运行环境进行管理。
Anaconda `国内镜像下载地址<https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/>`_ 下载完毕后
bash Anacoda......sh
使用Anaconda创建Merlin运行环境具体操作如下:
打开终端,使用下面命令查看一下现有python环境
conda env list
使用下面命令创建一个名为merlin的python环境
conda create --name merlin python=2.7
先进入merlin环境中
source activate merlin
在这个环境下安装merlin
sudo apt-get install csh cmake realpath autotools-dev automake
pip install numpy scipy matplotlib lxml theano bandmat
git clone https://github.com/CSTR-Edinburgh/merlin.git
cd merlin/tools
./compile_tools.sh
留意程序的输出结果,一些程序如果没有成功安装会影响到后面的结果
如果一切顺利,此时你已经成功地安装了Merlin,但要注意的是Merlin不是一个完整的TTS系统。它提供了核心的声学建模功能:语言特征矢量化,声学和语言特征归一化,神经网络声学模型训练和生成。但语音合成的前端(文本处理器)以及声码器需要另外配置安装。此外,Merlin目前仅提供了英文的语音合成。
此外,上述安装默认只配置支持CPU的theano,如果想要用GPU加速神经网络的训练,还需要进行其他的步骤。由于语料库的训练时间尚在笔者的接受范围之内(intel-i5,训练slt_arctic_full data需要大概6个小时),因此这里并没有使用GPU进行加速训练。
运行Merlin demo
sudo bash ~/merlin/egs/slt_arctic/s1/run_demo.sh
该脚本会使用50个音频样本进行声学模型和durarion模型的训练,并合成5个示例音频。在此略去详细的操作步骤,具体可参见:Getting started with the Merlin Speech Synthesis Toolkit installing-Merlin
2 Merlin源码理解¶
0 文件含义¶
| Folder | Contains |
|---|---|
| recordings | speech recordings, copied from the studio |
| wav | individual wav files for each utterance |
| pm | pitch marks |
| mfcc | MFCCs for use in automatic alignment mfcc tutorial |
| lab | label files from automatic alignment |
| utt | Festival utterance structures |
| f0 | Pitch contours |
| coef | MFCCs + f0, for the join cost |
| coef2 | coef2, but stripped of unnecessary frames to save space, for the join cost |
| lpc | LPCs and residuals, for waveform generation |
| bap | band aperiodicity |
1 免费的语料库¶
Merlin使用了网络上免费的语料库slt_arctic,可以在以下网址进行下载:slt_arctic_full_data.zip
2 训练数据的处理¶
Merlin自带的demo(merlin/egs/slt_arctic/s1 )已经事先完成了label文件以及声学参数mgc lf0 bap的提取,所以这里不需要前端FrontEnd和声码器对数据进行处理。
Merlin通过脚本文件setup.sh在~/merlin/egs/slt_arctic/s1 目录下创建目录experiments,在experiments目录下创建目录slt_arctic_demo,完成数据的下载与解压,并将解压后的数据分别放到slt_arctic_demo/acoustic_mode/data,slt_arctic_demo/duration_model/data目录下,分别用于声学模型和持续时间模型的训练。
3 Demo语料库的训练¶
run_demo.sh文件会进行语音的训练以及合成。这里有许多的工程实现细节,在这里略去说明,其主要进行了如下步骤 
其中语料库包含了文本和音频文件,文本需要首先通过前端FrontEnd处理成神经网络可接受的数据,这一步比较繁琐,不同语言也各不相同,下面会着重讲解。音频文件则通过声码器(这里使用的是STRAIGHT声码器)转换成声码器参数(包括了mfcc梅谱倒谱系数,f0基频,bap:band aperiodicity等)再参与到神经网络的训练之中。
4 Demo语料库的合成¶
Demo中提供了简单的合成方法,使用demo(merlin/egs/slt_arctic/s1 )下的脚本文件:merlin_synthesis.sh即可进行特定文本的语音合成。
同样的,由于merlin没有自带frontend,所以其demo中直接使用了事先经过frontend转换的label文件作为输入数据来合成语音。如果想要直接输入txt文本来获得语音,需要安装FrontEnd(下文会提及)并根据merlin_synthesis.sh文件的提示用FrontEnd来转换txt文本成label文件,再进行语音合成。
对于英文语音合成,merlin中需要首先通过Duration模型确定音素的发音时间,然后根据声学模型合成完整的语音。
5.Merlin的训练网络¶
Merlin的训练网络可见 *Merlin: An Open Source Neural Network Speech Synthesis System *
- Merlin一共提供了4类神经网络用于HMM模型的训练,分别是
- 前馈神经网络
- 基于LSTM的RNN网络
- 双向RNN网络
- 其他变体(如blstm)
3 Merlin 英文前端¶
Merlin前端FrontEnd
(1)Label的分类
- 在Merlin中,Label有两种类别,分别是
(2)txt to utt
文本到文本规范标注文件是非常重要的一步,这涉及自然语言处理,对于英文来说,具体工程实现可使用Festival,参见:Creating .utt Files for English
Festival 使用了英文词典,语言规范等文件,用最新的EHMM alignment工具将txt转换成包含了文本特征(如上下文,韵律等信息)的utt文件
(3)utt to label
在获得utt的基础上,需要对每个音素的上下文信息,韵律信息进行更为细致的整理,对于英文的工程实现可参见:Creating Label Files for Training Data
label文件的格式请参见:lab_format.pdf
(4)label to training-data(Question file)
The questions in the question file will be used to convert the full-context labels into binary and/or numerical features for vectorization. It is suggested to do a manual selection of the questions, as the number of questions will affect the dimensionality of the vectorized input features.
- 在Merlin目录下,merlin/misc/questions目录下,有两个不同的文件,分别是:
- questions-radio_dnn_416.hed
- questions-unilex_dnn_600.hed
查看这两个文件,我们不难发现,questions-radio_dnn_416.hed定义了一个416维度的向量,向量各个维度上的值由label文件来确定,也即是说,从label文件上提取必要的信息,我们可以很轻易的按照定义确定Merlin训练数据training-data;同理questions-unilex_dnn_600.hed确定了一个600维度的向量,各个维度上的值依旧是由label文件加以确定。
4 Merlin vocoder声码器¶
Merlin中自带的vocoder工具有以下三类:Straight,World,World_v2
这三类工具可以在Merlin的文件目录下找到,具体的路径如下merlin/misc/scripts/vocoder
在介绍三类vocoder之前,首先说明几个概念:
- MGC特征
- 通过语音提取的MFCC特征由于维度太高,并不适合直接放到网络上进行训练,所以就出现了MGC特征,将提取到的MFCC特征降维(在这三个声码器中MFCC都被统一将低到60维),以这60维度的数据进行训练就形成了我们所说的MGC特征
- BAP特征
- Band Aperiodicity的缩写
- LF0
- LF0是语音的基频特征
Straight
音频文件通过Straight声码器产生的是:60维的MGC特征,25维的BAP特征,以及1维的LF0特征。
通过 STRAIGHT 合成器提取的谱参数具有独特 特征(维数较高), 所以它不能直接用于 HTS 系统中, 需要使用 SPTK 工具将其特征参数降维, 转换为 HTS 训练中可用的 mgc(Mel-generalized cepstral)参数, 即, 就是由 STRAIGHT 频谱计算得到 mgc 频谱参数, 最后 利用原 STRAIGHT 合成器进行语音合成
World
音频文件通过World声码器产生的是:60维的MGC特征,可变维度的BAP特征以及1维的LF0特征,对于16kHz采样的音频信号,BAP的维度为1,对于48kHz采样的音频信号,BAP的维度为5
5 生成Merlin的英文label用于语音合成¶
注意到merlin是没有自带frontend的,对于英文,你需要安装Festival来将文本转换成HTS label, 对于其他语言,你需要自行设计或者找到支持的frontend,中文目前网络上还没有开源的工具,所以你需要自己设计
英文FrontEnd安装 具体步骤如下参见:Create_your_own_label_Using_Festival.md
安装完毕之后,参考merlin/tools/alignment 里面的文档生成自己的英文label
Merlin源码详解¶
关于merlin的详细解读(强烈推荐),可参考candlewill的[github gist](https://gist.github.com/candlewill/5584911728260904414b4a6679a93d53)
网络配置文件详解¶
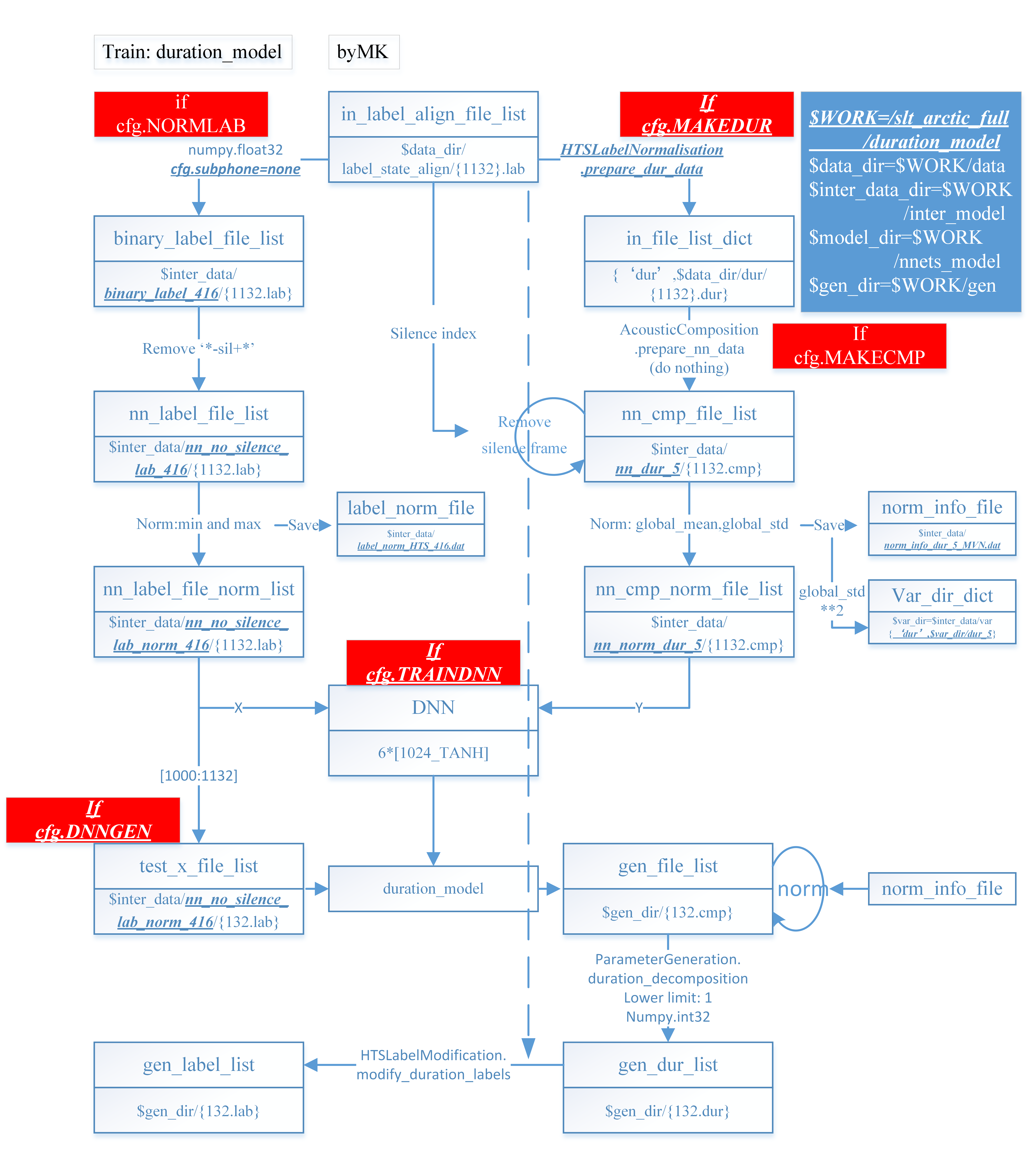
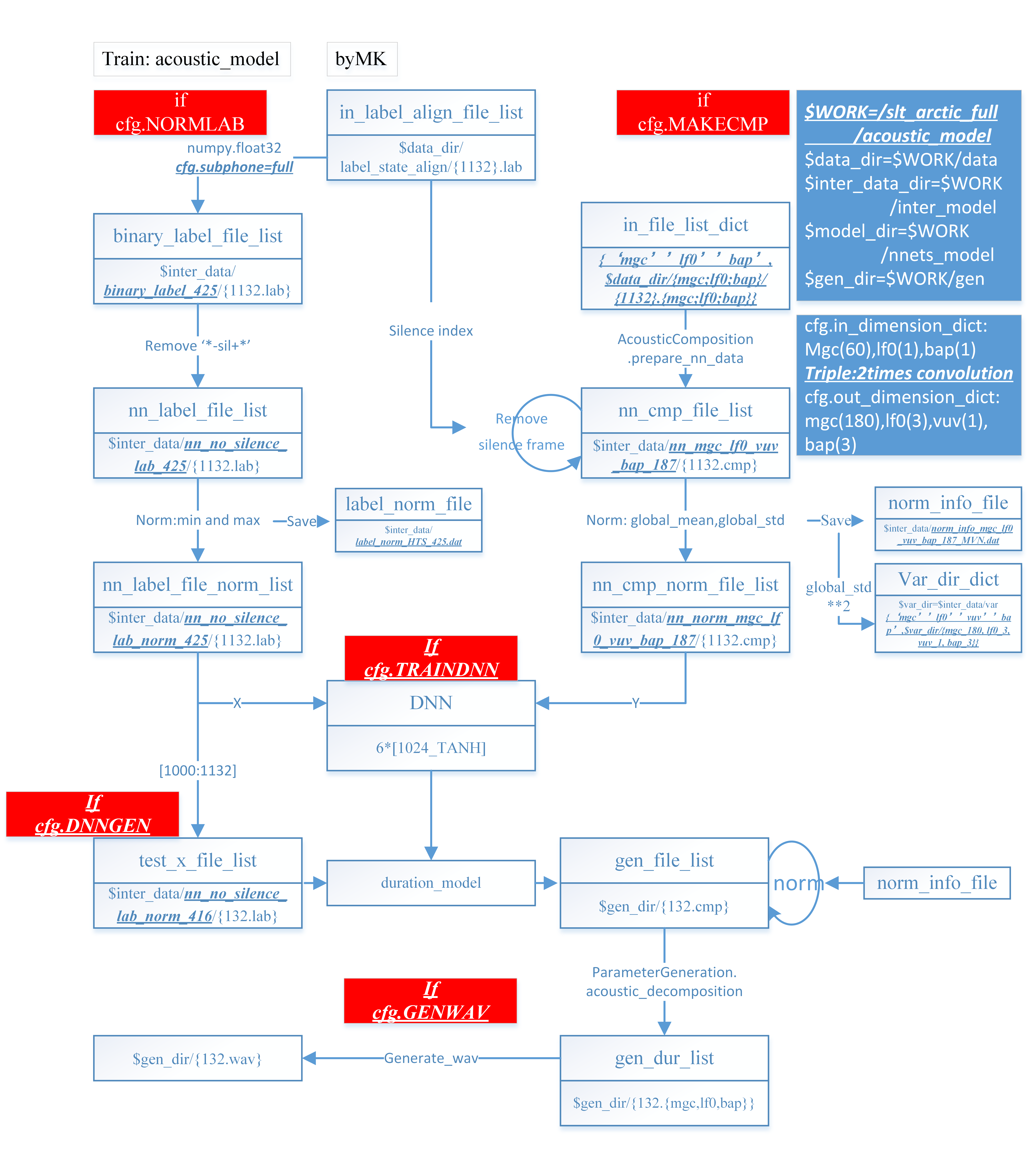
训练时长模型需要一个配置文件(后续的声学模型也一样)。一般而言,在一个样例配置文件上做一些修改即可。例如,训练DNN模型所用的样例配置文件为[duration_demo.conf](https://github.com/CSTR-Edinburgh/merlin/blob/master/misc/recipes/duration_demo.conf)。
Merlin称这些不同的样例配置文件为recipes,全部recipes可见:https://github.com/CSTR-Edinburgh/merlin/tree/master/misc/recipes 。
配置文件,主要包含路径信息、对齐方式、问题集名称、模型结构、数据划分、执行过程等信息。
run_merlin.py¶
程序执行入口,路径为:https://github.com/CSTR-Edinburgh/merlin/blob/master/src/run_merlin.py
执行过程¶
按照配置文件中不同的sub-processes,将会有不同的执行方式。
上述各个参数默认取值都为`False`,因此配置文件中只需要设置取值为`True`的参数即可。
训练时长模型,训练声学模型,测试时长模型,测试声学模型对应的配置文件,指定的执行流程,分别如下所示:
训练时长模型
NORMLAB : True
MAKEDUR : True
MAKECMP : True
NORMCMP : True
TRAINDNN : True
DNNGEN : True
CALMCD : True
训练声学模型
NORMLAB : True
MAKECMP : True
NORMCMP : True
TRAINDNN : True
DNNGEN : True
GENWAV : True
CALMCD : True
测试时长模型
NORMLAB: True
DNNGEN: True
测试声学模型
NORMLAB : True
DNNGEN : True
GENWAV : True